前言
目前大部分互联网架构 Cache 已经成为了必可不少的一环。常用的方案有大家熟知的 NoSQL 数据库(Redis、Memcached),也有大量的进程内缓存比如 EhCache 、Guava Cache、Caffeine 等。
本系列文章会选取本地缓存和分布式缓存(NoSQL)的优秀框架比较他们各自的优缺点、应用场景、项目中的最佳实践以及原理分析。本文主要针对本地 Cache 的老大哥 Guava Cache 进行介绍和分析。
基本用法
Guava Cache 通过简单好用的 Client 可以快速构造出符合需求的 Cache 对象,不需要过多复杂的配置,大多数情况就像构造一个 POJO 一样的简单。这里介绍两种构造 Cache 对象的方式:CacheLoader 和 Callable
CacheLoader
构造 LoadingCache 的关键在于实现 load 方法,也就是在需要 访问的缓存项不存在的时候 Cache 会自动调用 load 方法将数据加载到 Cache 中。这里你肯定会想假如有多个线程过来访问这个不存在的缓存项怎么办,也就是缓存的并发问题如何怎么处理是否需要人工介入,这些在下文中也会介绍到。
除了实现 load 方法之外还可以配置缓存相关的一些性质,比如过期加载策略、刷新策略 。
1 | private static final LoadingCache<String, String> CACHE = CacheBuilder |
Callable
除了在构造 Cache 对象的时候指定 load 方法来加载缓存外,我们亦可以在获取缓存项时指定载入缓存的方法,并且可以根据使用场景在不同的位置采用不同的加载方式。
比如在某些位置可以通过二级缓存加载不存在的缓存项,而有些位置则可以直接从 DB 加载缓存项。
1 | // 注意返回值是 Cache |
缓存项加载机制
如果某个缓存过期了或者缓存项不存在于缓存中,而恰巧此此时有大量请求过来请求这个缓存项,如果没有保护机制就会导致大量的线程同时请求数据源加载数据并生成缓存项,这就是所谓的 “缓存击穿” 。
举个简单的例子,某个时刻有 100 个请求同时请求 KEY_25487 这个缓存项,而不巧这个缓存项刚好失效了,那么这 100 个线程(如果有这么多机器和流量的话)就会同时从 DB 加载这个数据,很可怕的点在于就算某一个线程率先获取到数据生成了缓存项,其他的线程还是继续请求 DB 而不会走到缓存。
【缓存击穿图例】
看到上面这个图或许你已经有方法解这个问题了,如果多个线程过来如果我们 只让一个线程去加载数据生成缓存项,其他线程等待然后读取生成好的缓存项 岂不是就完美解决。那么恭喜你在这个问题上,和 Google 工程师的思路是一致的。不过采用这个方案,问题是解了但没有完全解,后面会说到它的缺陷。
其实 Guava Cache 在 load 的时候做了并发控制,在多个线程请求一个不存在或者过期的缓存项时保证只有一个线程进入 load 方法,其他线程等待直到缓存项被生成,这样就避免了大量的线程击穿缓存直达 DB 。不过试想下如果有上万 QPS 同时过来会有大量的线程阻塞导致线程无法释放,甚至会出现线程池满的尴尬场景,这也是说为什么这个方案解了 “缓存击穿” 问题但又没完全解。
上述机制其实就是 expireAfterWrite/expireAfterAccess 来控制的,如果你配置了过期策略对应的缓存项在过期后被访问就会走上述流程来加载缓存项。
缓存项刷新机制
缓存项的刷新和加载看起来是相似的,都是让缓存数据处于最新的状态。区别在于:
- 缓存项加载是一个被动 的过程,而 缓存刷新是一个主动触发 动作。如果缓存项不存在或者过期只有下次 get 的时候才会触发新值加载。而缓存刷新则更加主动替换缓存中的老值。
- 另外一个很重要点的在于,缓存刷新的项目一定是存在缓存中 的,他是对老值的替换而非是对 NULL 值的替换。
由于缓存项刷新的前提是该缓存项存在于缓存中,那么缓存的刷新就不用像缓存加载的流程一样让其他线程等待而是允许一个线程去数据源获取数据,其他线程都先返回老值直到异步线程生成了新缓存项。
这个方案完美解决了上述遇到的 “缓存击穿” 问题,不过 他的前提是已经生成缓存项了 。在实际生产情况下我们可以做 缓存预热 ,提前生成缓存项,避免流量洪峰造成的线程堆积。
这套机制在 Guava Cache 中是通过 refreshAfterWrite 实现的,在配置刷新策略后,对应的缓存项会按照设定的时间定时刷新,避免线程阻塞的同时保证缓存项处于最新状态。
但他也不是完美的,比如他的限制是缓存项已经生成,并且 如果恰巧你运气不好,大量的缓存项同时需要刷新或者过期, 就会有大量的线程请求 DB,这就是常说的 “缓存血崩” 。
缓存项异步刷新机制
上面说到缓存项大面积失效或者刷新会导致雪崩,那么就只能限制访问 DB 的数量了,位置有三个地方:
源头:因为加载缓存的线程就是前台请求线程,所以如果 控制请求线程数量 的确是减少大面积失效对 DB 的请求,那这样一来就不存在高并发请求,就算不用缓存都可以。
中间层缓冲:因为请求线程和访问 DB 的线程是同一个,假如在 中间加一层缓冲,通过一个后台线程池去异步刷新缓存 所有请求线程直接返回老值,这样对于 DB 的访问的流量就可以被后台线程池的池大小控住。
底层:直接 控 DB 连接池的池大小,这样访问 DB 的连接数自然就少了,但是如果大量请求到连接池发现获取不到连接程序一样会出现连接池满的问题,会有大量连接被拒绝的异常。
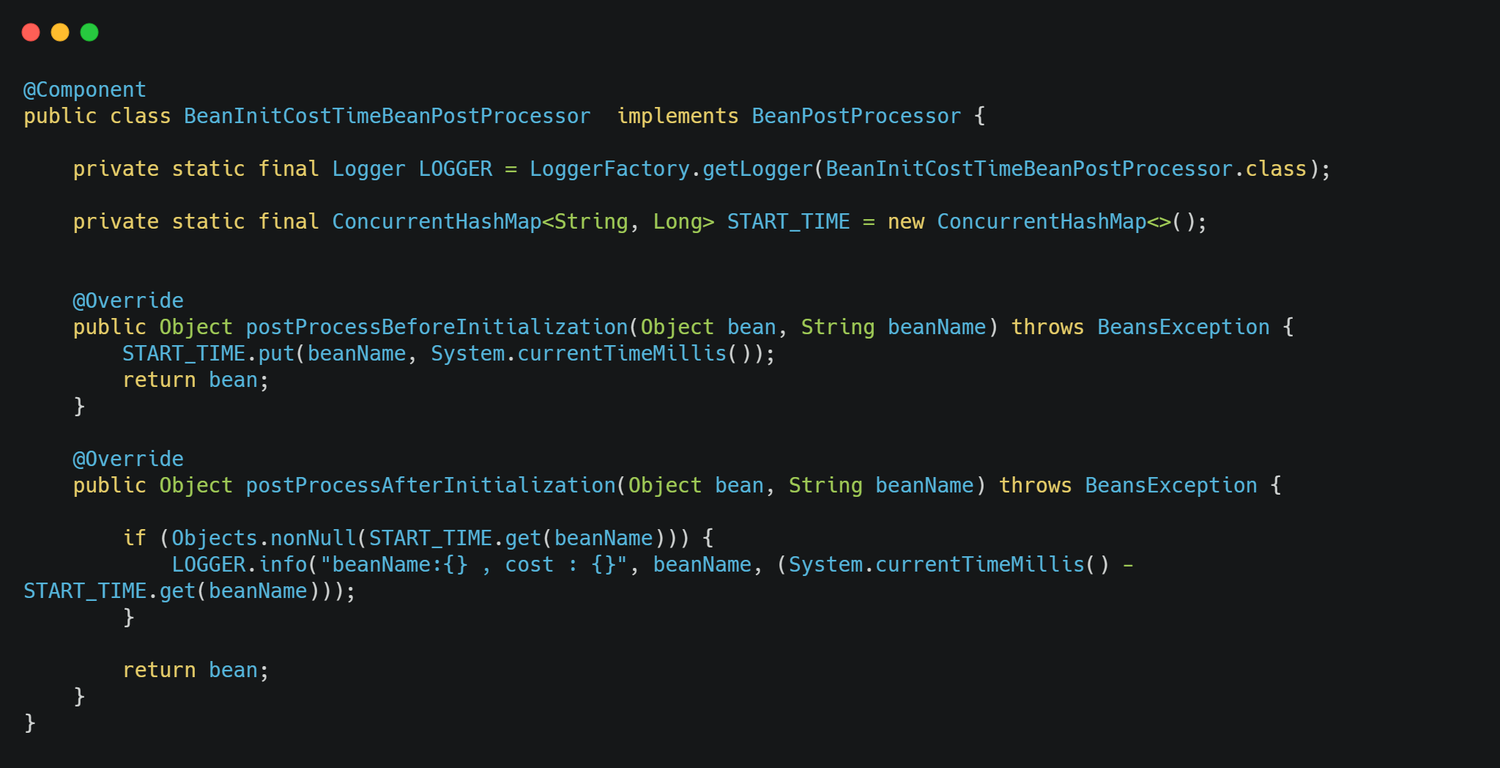
所以比较合适的方式是通过添加一个异步线程池异步刷新数据,在 Guava Cache 中实现方案是重写 CacheLoader 的 reload 方法 。
1 | private static final LoadingCache<String, String> ASYNC_CACHE = CacheBuilder.newBuilder() |
LocalCache 源码分析
先整体看下 Cache 的类结构,下面的这些子类表示了不同的创建方式本质还都是 LocalCache
【Cache 类图】
核心代码都在 LocalCache 这个文件中,并且通过这个继承关系可以看出 Guava Cache 的本质就是 ConcurrentMap。
【LocalCache 继承与实现】
在看源码之前先理一下流程,先理清思路。如果想直接看源码理解流程可以先跳过这张图 ~
【 get 缓存数据流程图】
这里核心理一下 Get 的流程,put 阶段比较简单就不做分析了。
LocalCache#get
1 | V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException { |
Segment#get
1 | V get(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException { |
Segment#scheduleRefresh
1 | // com.google.common.cache.LocalCache.Segment#scheduleRefresh |
Segment#waitForLoadingValue
1 | V waitForLoadingValue(ReferenceEntry<K, V> e, K key, ValueReference<K, V> valueReference) |
Segment#lockedGetOrLoad
1 | V lockedGetOrLoad(K key, int hash, CacheLoader<? super K, V> loader) throws ExecutionException { |
总结
结合上面图以及源码我们发现在整个流程中 GuavaCache 是没有额外的线程去做数据清理和刷新的,基本都是通过 Get 方法来触发这些动作 ,减少了设计的复杂性和降低了系统开销。
简单回顾下 Get 的流程以及在每个阶段做的事情,返回的值。首先判断缓存是否过期然后判断是否需要刷新,如果过期了就调用 loading 去同步加载数据(其他线程阻塞),如果是仅仅需要刷新调用 reloading 异步加载(其他线程返回老值)。
所以如果 refreshTime > expireTime 意味着永远走不到缓存刷新逻辑,缓存刷新是为了在缓存有效期内尽量保证缓存数据一致性所以在配置刷新策略和过期策略时一定保证 refreshTime < expireTime 。
最后关于 Guava Cache 的使用建议 (最佳实践) :
- 如果刷新时间配置的较短一定要重载 reload 异步加载数据的方法,传入一个自定义线程池保护 DB
- 失效时间一定要大于刷新时间
- 如果是常驻内存的一些少量数据失效时间可以配置的较长刷新时间配置短一点 (根据业务对缓存失效容忍度)