1. 基本原理 其实在 SparkStreaming 中和之前的Core不同的就是他会把任务分成批次的进行处理,也就是我们需要设置间隔多久计算一次。
我们从网络,文件系统,Kafka 等等数据源产生的地方获取数据,然后SparkStreaming放到内存中,接着进行对数据进行计算,获取结果。
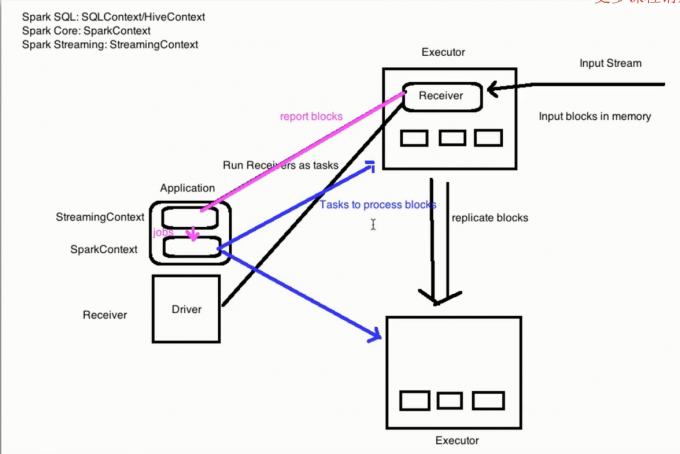
在一个Spark应用程序启动以后会产生一个SparkContext和一个StreamingContext,后者是基于前者的,接着就是每一个集群的单节点上就有Executor 这些Executor中是有Receiver的,然后这些Receiver就负责来自于网络以及Kafka等等的数据源的数据收集,这些数据会被拆分成Block分发到各个集群节点上,最后Receiver就把这些block信息发给StreamingContext 他会把告诉 SparkContext 去处理 job ,然后SparkContext 就启动 job 分配给 Executor
2. 基本概念 1. StreamingContext 这个东西就相当于所有的 Streaming 任务的主入口,所有的 Streaming 任务都需要他来完成。这个东西在定义以后我们书写计算任务的计划,完成之后我们不能在代码中 stop 后继续 start Streaming ,也就是没办法重启,只能在命令行重启。然后再JVM中只能存在一个此对象。
2. DStream 这个东西其实就相当于一个RDD的小截断,我们可以把数据想象成一个流,然后我们从里面截取一小段流就是我们说的 DStream ,然后 里面包含的就是各个 RDD。所以说如果我们队一个DStream 进行一个操作就相当于我们对里面的所有的RDD进行操作。那么这个DStream的长度是多少?这就是我们定义的计算的长度,也就是多久计算一次。
其实在每一个DStream中都包含了一个Receiver,但是除了FileDStream。这个Receiver就是从各个数据源进行获取数据用的, 他会把数据源获取的数据放到内存里面,但是我们文件系统中的数据我们可以直接处理而不需要收集这些数据。
我们基本的Receiver就是文件系统和TCP,然后我们有一些高级的就是 Flume 和 Kafka 等等。
注意一点就是我们在运行这些任务的时候我们不能写 local 或者 local[1] 因为我们在处理的时候必须要有两个线程以上,一个需要进行Receiver另外一个是数据计算。
4. 带状态的数据处理 UpdateStateByKey 1 2 3 4 5 6 7 8 9 10 11 12 13 def updateFunction Seq [Int ],preValues:Option [Int ]):Option [Int ]={ val current=currentValues.sum val pre=preValues.getOrElse(0 ) Some (current+pre) }
要注意一点的就是当我们使用了带有状态的算子我们必须要使用,checkpoint 才行,也就是需要创建一个checkpoint目录,否则或报错。
5. 窗口计算 窗口计算说的简单点其实就是说每隔多少秒计算多少秒内的结果。windowLength 和 interval 也就是每隔 interval 计算 windowLength 的长度的窗口。
算子在常用的加上一个AndWindow 官网有。
3. 黑名单的例子 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 object BlackFilter def main Array [String ]): Unit = { System .setProperty("hadoop.home.dir" , "D:\\hadoop\\winutils\\hadoop-2.8.3" ) val conf: SparkConf = new SparkConf ().setAppName("black" ).setMaster("local[*]" ) val session: SparkSession = SparkSession .builder.config(conf).getOrCreate() val sc: SparkContext = session.sparkContext val ssc = new StreamingContext (sc,Seconds (5 )) val blackList: RDD [(String , Boolean )] = sc.parallelize(List ("zs" , "ls" )).map((_, true )) val logs: ReceiverInputDStream [String ] = ssc.socketTextStream("master" ,6700 ) val clicklog=logs.map(log=>(log.split("," )(1 ),log)).transform(rdd=>{ rdd.leftOuterJoin(blackList) .filter(!_._2._2.getOrElse(false )) .map(_._2._1) }) clicklog.print() ssc.start() ssc.awaitTermination() } }
4. SparkStreaming和Flume整合 1. 配置 对于这个我们有两种配置方式,使用Flume的推送机制,也就是把我们的SparkStreaming作为一个avro的客户端来接受从channel过来的数据。
1. Flume 的推送机制 我们把SparkStreaming作为一个avro的客户端,来接受数据进行处理。由于是push的模型,我们的SparkStreaming必须先启动。
1. 配置Flume的配置文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 netcat-memcory-avro.sources = netcat-source netcat-memcory-avro.sinks = avro-sink netcat-memcory-avro.channels = memory-channel netcat-memcory-avro.sources.netcat-source.type = netcat netcat-memcory-avro.sources.netcat-source.bind = master netcat-memcory-avro.sources.netcat-source.port = 44444 netcat-memcory-avro.sinks.avro-sink.type = avro netcat-memcory-avro.sinks.avro-sink.hostname = master netcat-memcory-avro.sinks.avro-sink.port = 44445 netcat-memcory-avro.channels.memory-channel.type = memory netcat-memcory-avro.channels.memory-channel.capacity = 1000 netcat-memcory-avro.channels.memory-channel.transactionCapacity = 100 netcat-memcory-avro.sources.netcat-source.channels = memory-channel netcat-memcory-avro.sinks.avro-sink.channel = memory-channel
2 . Scala 代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 object FlumeWC { def main (args: Array[String]) : Unit = { System.setProperty("hadoop.home.dir" , "D:\\hadoop\\winutils\\hadoop-2.8.3" ) val conf: SparkConf = new SparkConf().setAppName("FlumeWC" ).setMaster("local[*]" ) val sc = new SparkContext(conf) val ssc = new StreamingContext(sc, Seconds(1 )) val stream: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createStream(ssc, "219.245.31.193" , 44445 ) val res: DStream[(String, Int)] =stream.map(x => new String(x.event.getBody.array).trim) .flatMap(_.split(" " )) .map((_, 1 )) .reduceByKey(_+_) res.print() ssc.start() ssc.awaitTermination() } }
2. 使用pull的方式 这种方式是Flume将数据sink到缓冲区中,然后我们使用Spark事务的去拉取数据,如果拉取到了才会删除那些在缓冲区的数据,也就是说这里的容错性更加的高,更可靠。
1. 配置文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 netcat-memcory-avro.sources = netcat-source netcat-memcory-avro.sinks = spark-sink netcat-memcory-avro.channels = memory-channel netcat-memcory-avro.sources.netcat-source.type = netcat netcat-memcory-avro.sources.netcat-source.bind = 127.0.0.1 netcat-memcory-avro.sources.netcat-source.port = 44444 netcat-memcory-avro.sinks.spark-sink.type = org.apache.spark.streaming.flume.sink.SparkSink netcat-memcory-avro.sinks.spark-sink.hostname = 219.245.31.193 netcat-memcory-avro.sinks.spark-sink.port = 44445 netcat-memcory-avro.channels.memory-channel.type = memory netcat-memcory-avro.channels.memory-channel.capacity = 1000 netcat-memcory-avro.channels.memory-channel.transactionCapacity = 100 netcat-memcory-avro.sources.netcat-source.channels = memory-channel netcat-memcory-avro.sinks.spark-sink.channel = memory-channel